In the early phases of machine learning, most systems were built as monolithic models trained once and then frozen. Over time, the industry evolved toward fine-tuning and task-specific variants. These models laid the groundwork for domain adaptation, but building useful AI applications today is about powering up the model to do more.
A powerful model is only one part of the equation. For AI systems to operate meaningfully in the real world, they must understand their problem space, interact with live data, retrieve historical context, and execute deterministic logic. Just as GPUs unlocked scale for training, the next leap is about unlocking interaction, attribution, and economic alignment at the application layer.
This is the infrastructure OpenLedger provides.
OpenLedger is the AI blockchain. It is designed not as a general-purpose chain, but as an execution and attribution layer for intelligent systems. It provides the substrate where models, data, memory, and agents become interoperable components. This blog details the tools that will extend models to enable a wide variety of agents and applications by adding the context, behavior, and memory they need.

Specialized Models (A Brief Recap)
The base of any intelligent application is a model. General-purpose models offer flexibility, but when applied to specialized domains, they benefit greatly from fine-tuning and adaptation. OpenLedger enhances this process through a dedicated pipeline:
-> Datanets which are curated, collaborative, and attributable data repositories built by community
-> Model Factory which simplifies fine-tuning using no-code workflows
-> OpenLoRA which hosts cost-effective adapter variants that can swap in real time, making inference lightweight and composable
These components have been discussed extensively in earlier posts. They serve as the foundation. And with the right extensions, they enable robust, intelligent agents to emerge.
Model Context Protocol (MCP)
For a model to open a file, read a database, or invoke a tool, it needs access to the external state and context. To give models this capability, OpenLedger introduces the Model Context Protocol (MCP).
MCP defines the structure for delivering context to a model and receiving structured responses that can be executed. It consists of three parts: a client that supplies data, a server that processes tool calls, and a router that manages the flow between them.
In practice, MCP has already been adopted in systems like Cursor, where an agent can read local files, edit codebases, and perform tool-based tasks inside the development environment. Tools like 21.dev act as MCP clients that can be added into Cursor to create dynamic, real-time interfaces. By using 21.dev, agents gain the ability to operate on live UI components, generating outputs that reflect real-time state with a visually rich layer.
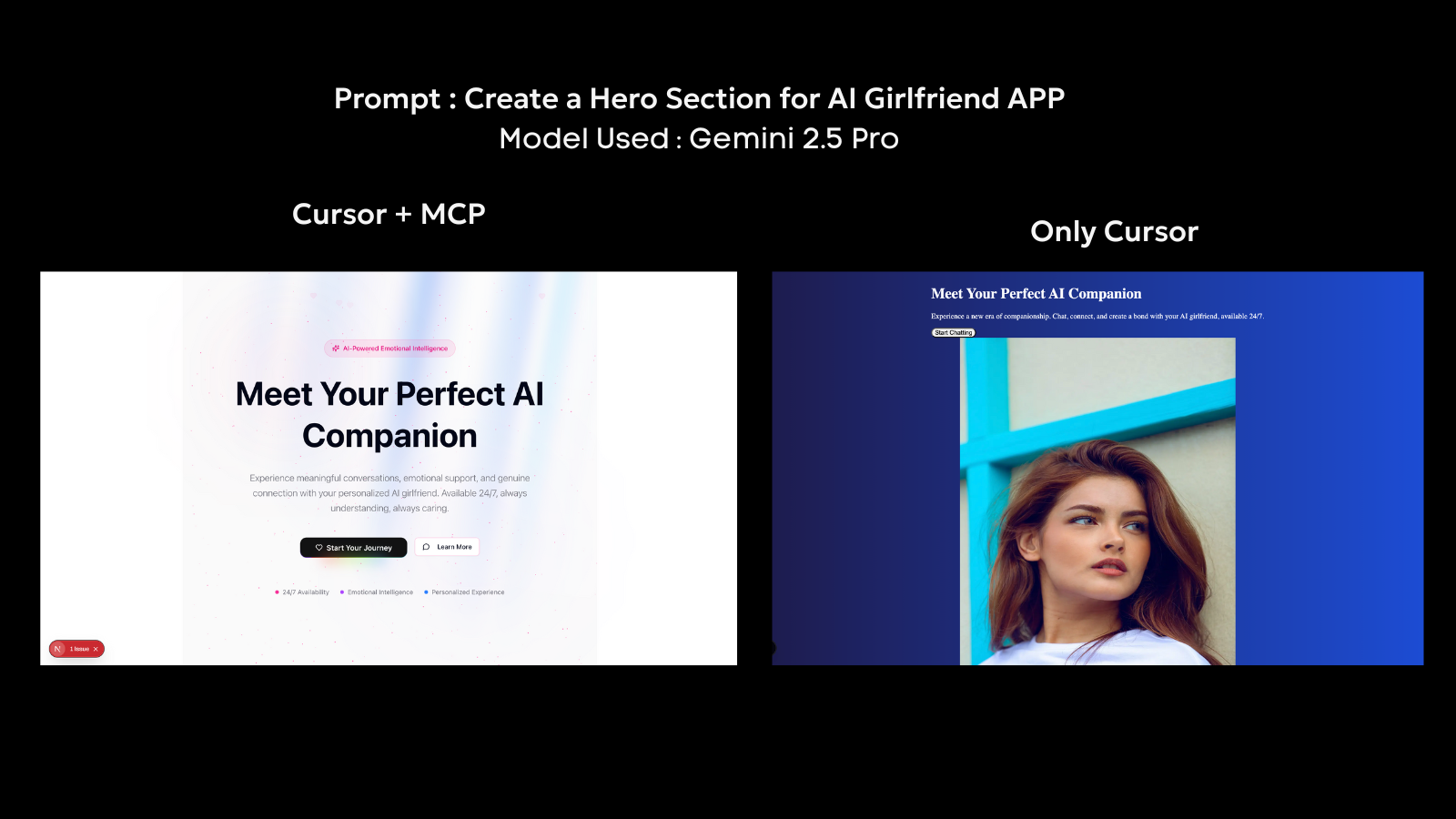
Future Vision for MCP with OpenLedger
OpenLedger envisions MCP evolving into an onchain registry. Every MCP tool can be registered, versioned, and attributed. Tools become composable components that any agent can invoke, with usage recorded and rewarded on chain. This allows developers to publish file readers, renderers, or API clients, and have them called by any OpenLedger-based agent with full attribution and traceability.
Retrieval-Augmented Generation
Some knowledge is too large, too detailed, or too frequently updated to be embedded directly into model weights. Yet it is foundational for reasoning. Retrieval-Augmented Generation (RAG) extends a model’s capability by introducing real-time, query-specific memory.
RAG separates storage from inference. Documents are embedded into vectors, indexed semantically, and retrieved at runtime based on the user’s query. The retrieved content is then injected into the prompt window, grounding the model’s response.
This method is especially relevant for domain-specific agents. An agent trained to understand a particular domain might access blog posts, documentation, proposals, and community threads. Instead of memorizing all this content, it queries a RAG system built from trusted sources. The response is accurate, up to date, and anchored in real evidence. This structure allows agents to avoid hallucinations, while enabling them to search, fetch, and reason across dynamic content.
Future Vision for RAG with OpenLedger
OpenLedger extends RAG into a collaborative and attributable layer. Just as with datasets and models, every document stored in a RAG index is attributed to its contributor. When the document is retrieved, that usage is recorded. This transforms RAG from a memory system into an incentive mechanism.
In the future, contributors will be able to register documents on-chain as part of a distributed knowledge graph. Each retrieval event will trigger micro-attributions, creating a transparent flow of credit and economic value tied to informational influence.
An OpenLedger-based agent trained on platform-specific content such as blog posts, documentation, governance proposals, and user conversations will not need to memorize all context. It can query a decentralized RAG system built from verified community sources. Each retrieved span links back to its author, enabling reward distribution even at inference time.
With OpenLedger’s infrastructure, RAG becomes a system for verifiable, incentivized reasoning. Every paragraph, citation, or data point can be traced, reused, and monetized in ways that reflect true influence across the agent ecosystem.
Prompts as Behavior Logic
The final layer of an intelligent agent is its behavior. This is not encoded in weights or data. It is defined through prompts.
A prompt structures the interaction. It tells the model how to think, how to format its output, and what constraints to follow. It acts as the logic layer that governs how inputs are interpreted and how tools are invoked. In complex agents, prompt design is not a one-time instruction. It can involve chains of structured templates, dynamic context fields, and planning instructions.
Prompt engineering allows developers to define agent behavior without changing the model itself. With the right design, agents become deterministic in their reasoning steps. Their outputs remain consistent, tool usage is scoped, and responses reflect both the given context and the intended goal.
Future Vision for Prompts with OpenLedger
OpenLedger treats prompts as programmable assets. In the future, this could lead to a smart contract standard for prompts, allowing them to be deployed, versioned, and referenced directly on chain. Prompts would become first-class building blocks in agent development, with attribution and reusability baked into their design.
A prompt registry on OpenLedger would let developers create and publish reusable templates tied to specific tasks, tools, or models. These templates could be linked to agents, updated over time, and monetized based on usage.
Every prompt used by an agent could be traced back to its author. Attribution would be enforced at the infrastructure level, enabling fair rewards, transparent coordination, and behavior-level interoperability across agents. Prompts would no longer be static strings but dynamic, verifiable components of intelligent systems.
Case Study: Building a Community-Trained Trading Agent on OpenLedger
This is how a real trading agent can be built using OpenLedger. It starts with data, builds the model, adds live tools, and turns into a working application.
Step 1: Community Data Collection
The process starts with a Datanet. A Datanet is a community data collaboration platform. Traders from Discord, Twitter, and other communities contribute trading strategies, chart annotations, token analysis, and trade decisions. The Datanet owner reviews and verifies each submission. Once approved, the data is added to the Datanet and becomes part of a growing instruction dataset. Every contributor is recorded on chain.
Step 2: Train a Specialized Model
Using the verified data from the Datanet, a model is fine-tuned to understand trading patterns, how traders think, and how decisions are made. The model is deployed using OpenLoRA. This keeps the model lightweight, cheaper to run, and easy to update.
Step 3: Add Real-Time Context with MCP
The agent needs live market data to make decisions. Through the Model Context Protocol (MCP), it connects to:
-> CoinMarketCap for token prices
-> Binance and Coinbase for real-time trades
-> Kaito for trending mindshare on Twitter
-> Uniswap or PancakeSwap for on-chain liquidity
Every time a tool is used, attribution is recorded on chain.
Step 4: Use RAG for Market Memory
The agent also needs historical context. Using Retrieval-Augmented Generation (RAG), it pulls information such as:
-> Token whitepapers
-> DAO proposals
-> Governance decisions
-> Emission schedules
-> Records of past exploits or major events
This gives the agent full background knowledge on the tokens it analyzes.
Step 5: Define Agent Rules as Prompts
Prompts tell the agent how to combine all the data and make decisions. The agent checks prices, liquidity, sentiment, and token history.
-> If sentiment is high but governance is weak or there are past issues, it flags high risk
-> If volatility is high and sentiment is unclear, it waits.
-> If fundamentals and sentiment are strong, it suggests a possible entry.
The prompts are versioned, reusable, and fully attributed.
Step 6: Attribute Everything Onchain
Every dataset, tool, prompt, and document used by the agent is recorded on OpenLedger. Contributors automatically receive credit whenever their work powers an agent decision.
The Outcome
Community data becomes a fully functioning trading agent. It reads live markets, understands token history, applies reasoning, and makes clear decisions. Everything it does is transparent, traceable, and rewards every contributor involved. This is how agents are built on OpenLedger.
Conclusion
The next wave of AI will not stop at models. It will be shaped by systems that give models access to real-time context, long-term memory, clear behavior, and tool-based execution. These systems will produce agents that are transparent, attributed, and built to operate in the open.
OpenLedger is designed to support this shift. From community-curated Datanets and lightweight model adapters to the Model Context Protocol and Retrieval-Augmented Generation, we have built the infrastructure needed to turn models into fully functioning applications.
The goal is simple: make it easy for anyone to build agents that reason, act, and collaborate. Each component is modular. Every step is traceable. Contributors are rewarded automatically.
The tools are ready. The foundation is live. Now is the time to build with it.
If you are creating trading agents, research copilots, or decentralized applications, start building on OpenLedger. Deploy transparently. Attribute contributions. Build the future together